About Me
I am a PhD student at Mila Quebec AI Institute and Concordia University in Canada with a passion for deep learning and computer vision research. My primary research interest lies in improving the efficiency of training foundation models by leveraging prior knowledge through continual learning, meta-learning, and model reuse. I am being supervised by Dr.Eugene Belilovsky. Before coming to Mila and Concordia , I worked as a research intern at KAUST in Vision CAIR group under the supervision of Dr.Mohammed Elhoseiny. I did my undergraduate at University of Moratuwa, Sri Lanka with thesis in reconstructing 3D objects with few views with Dr. Thanuja Ambegoda.
Download my CV .
- Continual learning
- Meta learning
- Foundation models
- Computer vision
PhD in Computer Science, 2024-2028
Concordia University
Masters in Computer Science, 2023-2025
Concordia University
BSc in Computer science and Engineering, 2018-2023
University of Moratuwa
News
2025
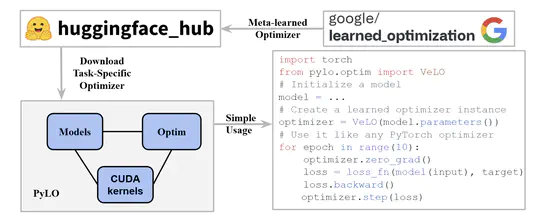
[2025-07-09] We released PyLO an open source optimization library to enable usage of learned optimizers in PyTorch
[2025-07-08] 2 papers accepted at ICML 2025 Workshops
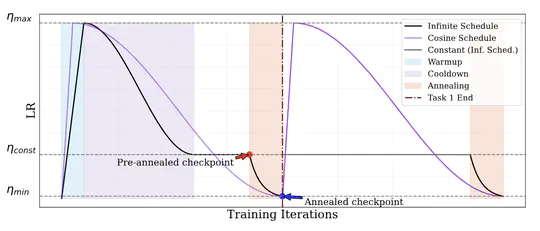
[2025-05-12] 1 paper accepted at CoLLAs 2025 Main Conference (oral)
2024
[2024-09-29] 1 paper accepted at ECCV 2024 Workshop
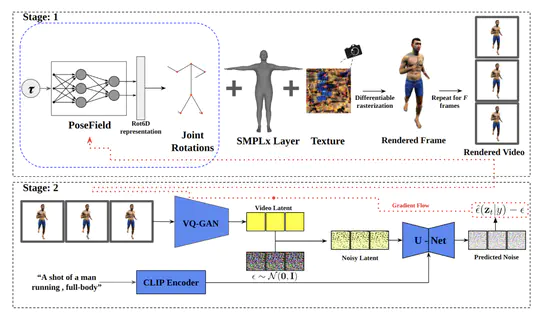
[2024-06-01] 1 paper accepted at CVPR 2024 Main Conference
[2024-05-01] Fast tracked to PhD in Computer science from MS under Dr.Eugene Belilovsky
2023
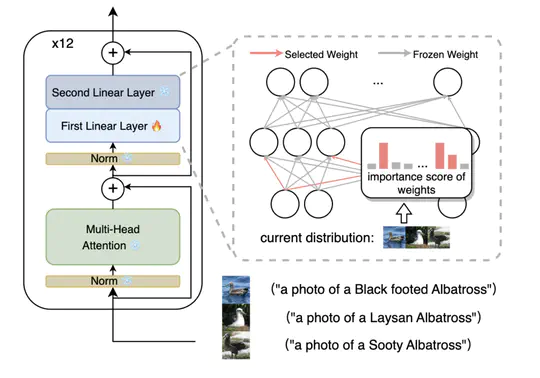
[2023-10-03] 2 papers accepted at ICCV 2023 Main conference and workshop
[2023-09-01] Started my MS in Computer Science at Mila and Concordia University under Dr.Eugene Belilovsky
2022
- [2022-10-20] 1 paper accepted at NeurIPS 2022 Workshop
Publications
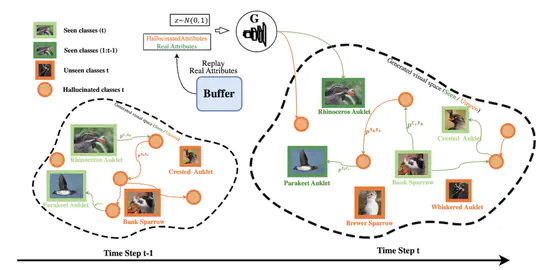
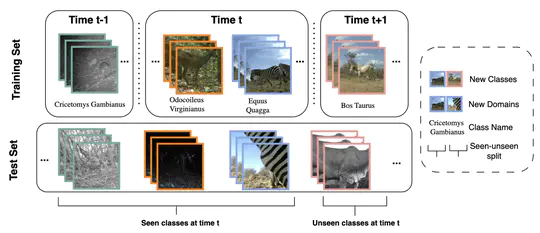
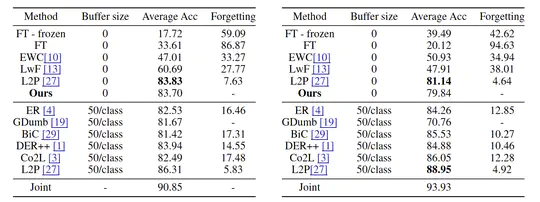
Experience
Contact
- paul.janson@mila.quebec
- +1 *******
- ER966, 2155 Guy Street, Montreal, QC H3G 1M8
- Book an appointment
- DM Me