Abstract
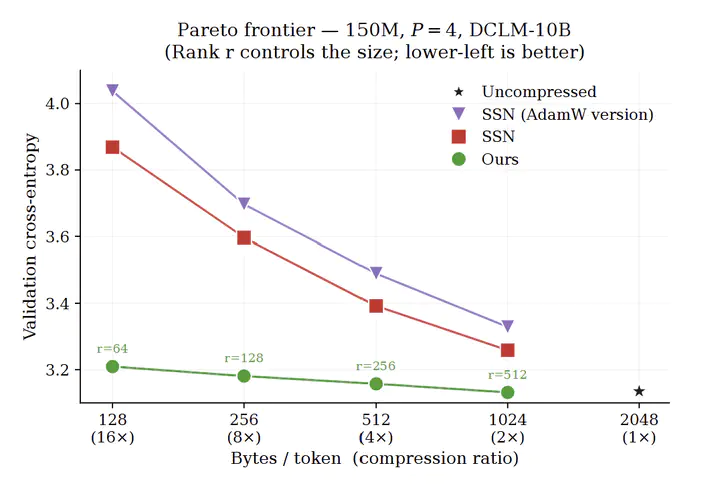
Pipeline parallelism enables training of large language models that exceed single-device memory, yet inter-stage activation communication becomes the dominant bottleneck when trained on low-bandwidth networks. Recent work in this area has proposed using fixed orthogonal projections to compress activations. However, this still results in a significant performance degradation and requires a number of non-standard adaptations to constrain the optimization. A natural alternative is to learn a low rank projection for each pipeline stage, however maintaining the necessary orthogonality of these projectors during training remains a challenge. We present Manifold Aware Projection Learning (MAPL), a method that treats inter-stage compression as a learnable orthogonal projection under explicit Stiefel manifold (orthogonal matrices) constraints. Rather than prescribing a fixed global subspace, MAPL lets each pipeline stage discover and continuously adapt its own task-optimal compression subspace via manifold-constrained steepest descent. To recover token-specific signals at stage boundaries, we introduce per-stage factorized anchor embeddings that allow for full-rank activation reconstruction with negligible communication overhead. We further show that we can incorporate residual vector quantization after projection with a streaming codebook synchronization protocol that amortizes dictionary communication. Across LLaMA models from 150M to 1B parameters we show that MAPL can be easily applied to the existing pipeline and can achieve high compression with negligible performance degradation with drastically improved tradeoffs in performance vs. compression compared to Subspace Networks.
Paul Janson
PhD Student
My research interests lies in the conjunction of computer vision and deep learning. Mainly continual learning, meta-learning and diffusion models.