Abstract
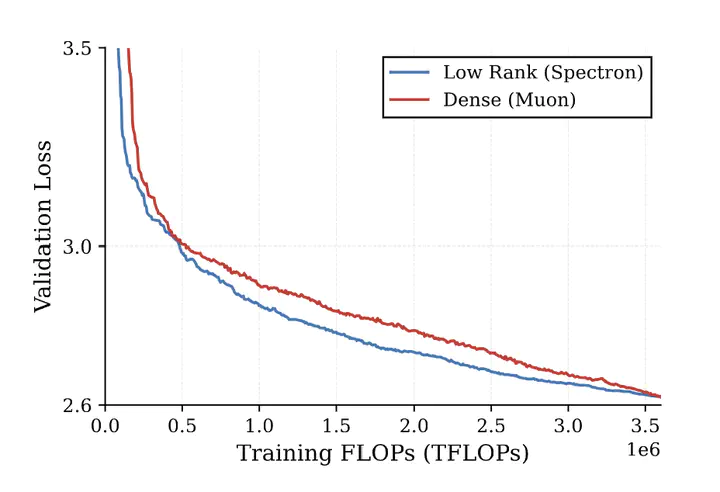
Training large language models using exclusively low-rank factorized weights promises substantial savings in memory and inference cost, but remains plagued by instability. We identify uncontrolled growth in the spectral norm of weight matrix updates as the primary source of this instability when training natively factorized models end-to-end. To address it, we introduce Spectron, a spectral renormalization technique with orthogonalization that dynamically constrains weight updates based on the current spectral norms of the factors. Spectron enables stable end-to-end factorized training with minimal computational overhead. We further establish compute-optimal scaling laws for natively low-rank models, demonstrating predictable power-law behavior and improved inference efficiency compared to dense models.
Paul Janson
PhD Student
My research interests lies in the conjunction of computer vision and deep learning. Mainly continual learning, meta-learning and diffusion models.