Abstract
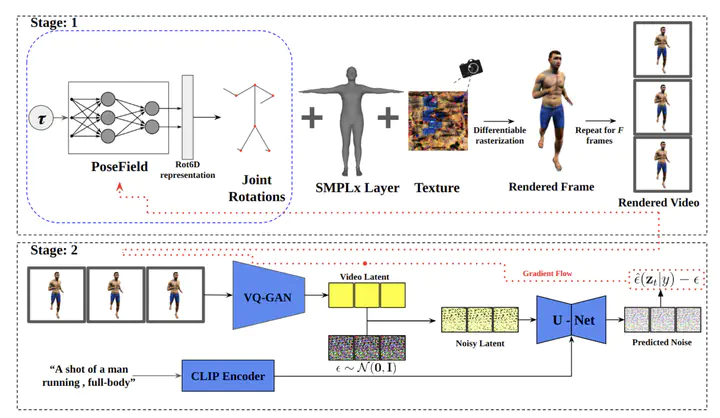
Video diffusion models have emerged as a powerful tool in the realm of video generation and editing, raising the question of their ability to comprehend and replicate human motion accurately. These models leverage diffusion processes to iteratively transform random noise into coherent video sequences guided by a text prompt, but the extent to which they grasp the intricacies of human movement remains under investigation. This study employs an ‘analysis by synthesis’ approach, where the performance of video diffusion models is evaluated by synthesizing human motion and comparing it qualitatively. We examine the publicly available text-to-video diffusion models’ capacity to generate natural and diverse motions. This offers insights into potential future directions for enhancing their performance in generating plausible human motion.
Paul Janson
PhD Student
My research interests lies in the conjunction of computer vision and deep learning. Mainly continual learning, meta-learning and diffusion models.